
For this blog, let’s wear the Developer DBA hat and discuss how we can use T-SQL to transpose columns to rows using PIVOT and UNPTVOT operator (for MSSQL 2012 and newer).
To be more specific, assuming that we got the end result of ETL process with various Stats with their datetime info as following
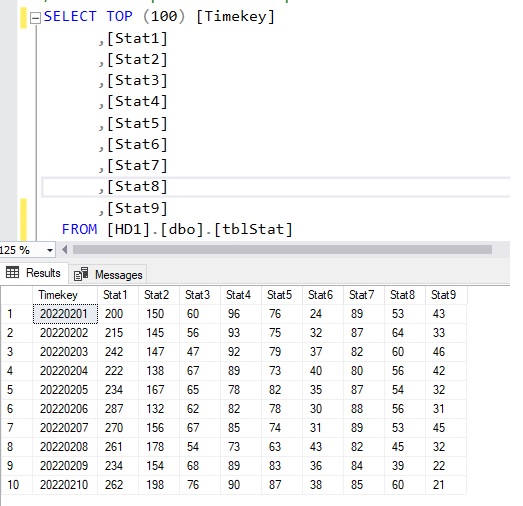
whereas each row represents 1 day of various stats for the day. And then on one beautiful day your boss wanna review the result as something like below due to the water-fall dependency of those stats e.g. Stat3 = Stat4 + Stat5 etc.
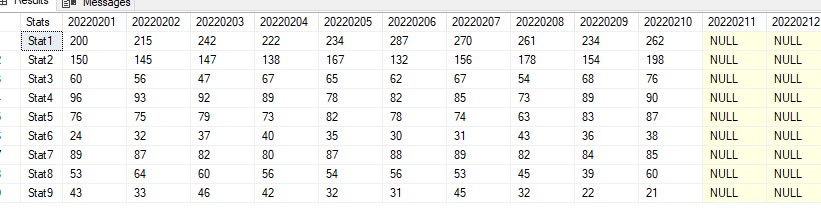
While Excel can accomplish this request easily, we are database professional and willing to take the challenge to tackle this issue using T-SQL, aren’t we?
What will be the T-SQL query then?
You can refer to the answer using CTE + PIVOT + UNPIVOT below (pardon the misalignment, I am still figuring out how to make it what-you-type-is-what-you-see)
WITH HD_CTE AS
(
SELECT Timekey,[Stats], [Value]
FROM [HD1].[dbo].[tblStat]
UNPIVOT ( [Value] FOR [Stats] IN (
[Stat1]
,[Stat2]
,[Stat3]
,[Stat4]
,[Stat5]
,[Stat6]
,[Stat7]
,[Stat8]
,[Stat9]
)) AS U
)
SELECT Stats,
[20220201],[20220202],[20220203], [20220204], [20220205], [20220206], [20220207],[20220208],[20220209],
[20220210],
[20220211],[20220212],[20220213], [20220214], [20220215], [20220216], [20220217],[20220218],[20220219],
[20220220],
[20220221],[20220222],[20220223], [20220224], [20220225], [20220226], [20220227],[20220228]
FROM HD_CTE
PIVOT (SUM(VALUE) FOR Timekey IN (
[20220201],[20220202],[20220203], [20220204], [20220205], [20220206], [20220207],[20220208],[20220209],
[20220210],
[20220211],[20220212],[20220213], [20220214], [20220215], [20220216], [20220217],[20220218],[20220219],
[20220220],
[20220221],[20220222],[20220223], [20220224], [20220225], [20220226], [20220227],[20220228]
)
) AS P
ORDER BY Stats
1 area of improvement can be the dynamic population of YYYYMMDD based on the input parameter of month and year.
Using Python instead of T-SQL
There is a saying ‘There are more than one way to skin a cat’ whereas we can use Python and leverage on the pandas library since it allows a single DataFrame function (.T) to accomplish the same result with the lengthy T-SQL script above. Full code can be found below
import pyodbc
import pandas as pd
# Reading the data from SQL Server
con = pyodbc.connect('DRIVER={ODBC Driver 17 for SQL Server};SERVER=localhost;DATABASE=HD1;UID=apps_login;PWD=apps_login')
query = """
SELECT [Timekey]
,[Stat1]
,[Stat2]
,[Stat3]
,[Stat4]
,[Stat5]
,[Stat6]
,[Stat7]
,[Stat8]
,[Stat9]
FROM [HD1].[dbo].[tblStat]
WHERE [Timekey] LIKE '202202%'
"""
TM = pd.read_sql(query, con)
# Transpose the original DataFrame TM into to TM_transposed
TM_transposed = TM.T
TM_transposed
Hoping you like this blog post and feel free to share any comments/feedbacks below.
Thank you for your time.